Comparing Evaluation Results Over Time
How updates to evaluation tasks can invalidate comparisons across models and time, and strategies for maintaining comparability.
This document explains how updates to evaluation tasks can invalidate comparisons across models and time, and provides strategies for maintaining comparability.
Each task carries a version in N-X format (e.g. 3-A), where N tracks comparability-breaking changes and X tracks interface changes. See TASK_VERSIONING.md for the full versioning policy.
When N changes between two evaluation runs, their results may not be directly comparable. Without version-aware evaluation, score changes may be incorrectly attributed to model improvements rather than changes in the evaluation itself.
Setup
python -m venv .venv
source .venv/bin/activate
pip install inspect-evals[mle_bench]Evaluate GPT-4o
from inspect_evals.mle_bench import mle_bench
from inspect_ai import eval as _eval
log = _eval(
mle_bench(split="low.txt"),
model="openai/gpt-4o",
)mle_bench_scorer valid_submission
accuracy 0.909
stderr 0.061Columns are truncated for brevity; actual output includes additional metrics.
Example numbers are illustrative; your exact scores will vary.
Note: stderr captures sampling uncertainty. Treat differences within ~2× stderr as noise; increase sample size if you need tighter comparisons.
Note the task version via the inspect log viewer (use inspect view; uv run inspect view only if you are running from the repo environment):
inspect view{
"task": "inspect_evals/mle_bench",
"task_version": 3,
"metadata": {
"full_task_version": "3-A",
"task_interface_version": "A",
"task_comparability_version": 3
},
"packages": {
"inspect_evals": "...",
"inspect_ai": "..."
}
}The comparability version is 3.
Upgrade inspect_evals
Upgrading inspect-evals can change evaluation results due to bug fixes, timeout adjustments, or dataset changes. A change to the comparability version (N in N-X) signals that results may no longer be comparable with the prior version.
pip install --upgrade inspect-evals[mle_bench]Evaluate GPT-5 after upgrading
from inspect_evals.mle_bench import mle_bench
from inspect_ai import eval as _eval
log = _eval(
mle_bench(split="low.txt"),
model="openai/gpt-5",
)mle_bench_scorer valid_submission
accuracy 0.955
stderr 0.044{
"task": "inspect_evals/mle_bench",
"task_version": 4,
"metadata": {
"full_task_version": "4-B",
"task_interface_version": "B",
"task_comparability_version": 4
},
"packages": {
"inspect_evals": "...",
"inspect_ai": "..."
}
}The comparability version is now 4. This differs from the earlier run (3).
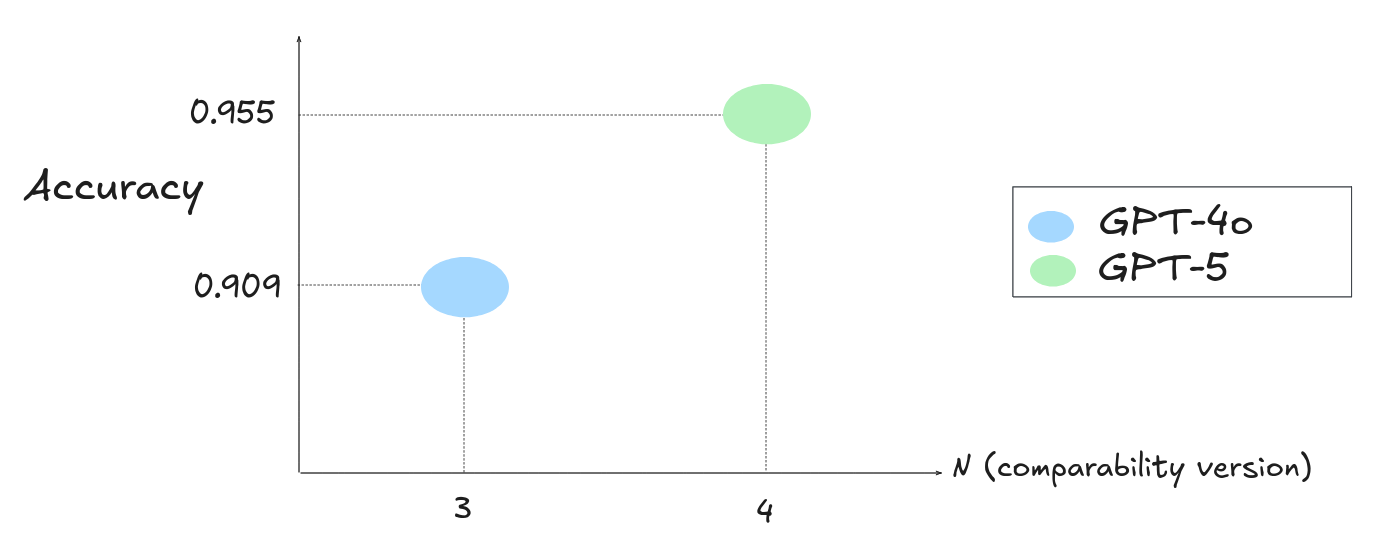
Investigating task version differences
When comparability versions differ between runs, check whether the underlying changes could affect the fairness of cross-model or cross-time comparisons.
Check the eval’s changelog
Each eval’s README contains a changelog that documents version bumps with links to associated PRs.
The MLE-Bench changelog shows what changed between versions:
### [4-B] - 2026-02-26
- Bump per-sample timeout to 6 minutes.
- Add configurable CPU and memory.
- Make dataset downloading lazy.
### [3-A] - 2026-02-19
- Bugfix: Skip the `the-icml-2013-whale-challenge-right-whale-redux` competition due to being unavailable.The 3-A to 4-B version bump increased the per-sample timeout to 6 minutes. This directly affects comparability: a model with more time may produce better submissions and score higher.
The score improvement from GPT-4o to GPT-5 could be partly or wholly attributable to the longer timeout rather than model capability.
For how to locate specific historical commits, see Running a specific version.
Maintaining comparability
When is action needed?
The N-X version has two independent components:
N(comparability version) — changes that affect evaluation results (scoring logic, dataset changes, timeouts, prompt changes). WhenNdiffers between two runs, their scores may not be fairly compared.X(interface version) — changes to the task’s calling interface (renamed parameters, new options). These do not affect scores, only how the task is invoked.
Only changes to N require action. If only X has changed (e.g. 3-A to 3-B), existing results remain comparable — you may just need to update your invocation to match the new interface.
When N does change, there are two approaches. Both involve re-running evaluations, which can be expensive — especially for agent benchmarks or large datasets.
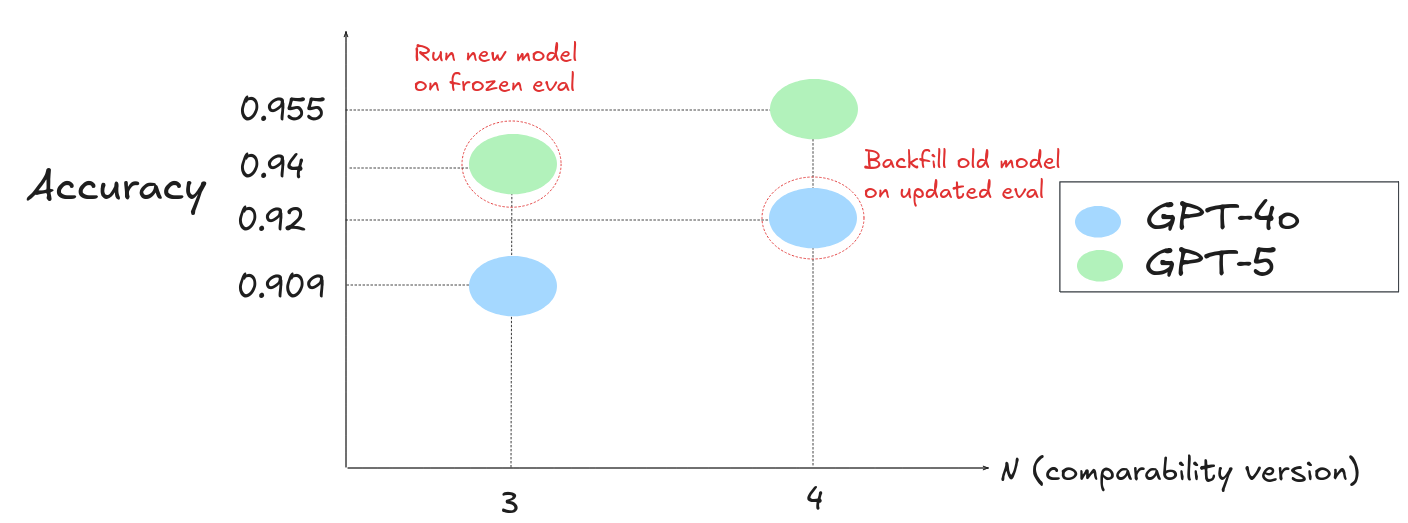
Backfill older models using the new evaluation version
Re-run the older model on the current evaluation version so both results share the same comparability version. This means re-evaluating every model you want to compare against.
from inspect_evals.mle_bench import mle_bench
from inspect_ai import eval as _eval
log = _eval(
mle_bench(split="low.txt"),
model="openai/gpt-4o",
)mle_bench_scorer valid_submission
accuracy 0.920
stderr 0.06Both GPT-4o and GPT-5 are now evaluated at comparability version 4, making the results directly comparable.
If the backfilled scores are close, treat differences within the reported stderr as noise rather than a real performance gap.
Freeze the evaluation version for new models
Install the older version of inspect-evals to evaluate new models at the same task version. See Running a specific version for details on pinning to a specific commit.
pip install "inspect-evals[mle_bench]==<older_version>"from inspect_evals.mle_bench import mle_bench
from inspect_ai import eval as _eval
log = _eval(
mle_bench(split="low.txt"),
model="openai/gpt-5",
)As with backfill, treat differences within the reported stderr as noise.
mle_bench_scorer valid_submission
accuracy 0.940
stderr 0.07Both models are now evaluated at comparability version 3, making the results directly comparable.