SWE-bench Verified: Resolving Real-World GitHub Issues
Evaluates AI’s ability to resolve genuine software engineering issues sourced from 12 popular Python GitHub repositories, reflecting realistic coding and debugging scenarios.
Overview
This is an inspect-native implementation of the SWE-bench dataset, a benchmark for testing the ability of AI agents to solve software engineering tasks.
Usage
Installation
There are two ways of using Inspect Evals, from pypi as a dependency of your own project and as a standalone checked out GitHub repository.
If you are using it from pypi, install the package and its dependencies via:
pip install inspect-evals[swe_bench]If you are using Inspect Evals in its repository, start by installing the necessary dependencies with:
uv sync --extra swe_benchRunning evaluations
Now you can start evaluating models. For simplicity’s sake, this section assumes you are using Inspect Evals from the standalone repo. If that’s not the case and you are not using uv to manage dependencies in your own project, you can use the same commands with uv run dropped.
uv run inspect eval inspect_evals/swe_bench --model openai/gpt-5-nano
uv run inspect eval inspect_evals/swe_bench_verified_mini --model openai/gpt-5-nanoTo run multiple tasks simulteneously use inspect eval-set:
uv run inspect eval-set inspect_evals/swe_bench inspect_evals/swe_bench_verified_miniYou can also import tasks as normal Python objects and run them from python:
from inspect_ai import eval, eval_set
from inspect_evals.swe_bench import swe_bench, swe_bench_verified_mini
eval(swe_bench)
eval_set([swe_bench, swe_bench_verified_mini], log_dir='logs-run-42')After running evaluations, you can view their logs using the inspect view command:
uv run inspect viewFor VS Code, you can also download Inspect AI extension for viewing logs.
If you don’t want to specify the --model each time you run an evaluation, create a .env configuration file in your working directory that defines the INSPECT_EVAL_MODEL environment variable along with your API key. For example:
INSPECT_EVAL_MODEL=anthropic/claude-opus-4-1-20250805
ANTHROPIC_API_KEY=<anthropic-api-key>[!NOTE] SWE-bench uses pre-built Docker images from Epoch AI’s ghcr.io registry by default. You need to authenticate with ghcr.io first:
gh auth token | docker login ghcr.io -u USERNAME --password-stdinSee: https://epoch.ai/blog/swebench-docker
SWE-bench will take a while to run, and uses a lot of tokens. If things are too slow, you should increase the level of parallelism - see https://inspect.ai-safety-institute.org.uk/parallelism.html. Note that running too many docker containers on your machine can also cause issues, most notably with a ‘ALL PREDEFINED ADDRESS POOLS HAVE BEEN FULLY SUBNETTED’ error - we don’t recommend running more than 32 containers at any one time.
Options
You can control a variety of options from the command line. For example:
uv run inspect eval inspect_evals/swe_bench --limit 10
uv run inspect eval inspect_evals/swe_bench_verified_mini --max-connections 10
uv run inspect eval inspect_evals/swe_bench --temperature 0.5See uv run inspect eval --help for all available options.
Parameters
swe_bench
dataset(str): The dataset to use. Either a HuggingFace dataset name or a path to a dataset on disk. (default:'princeton-nlp/SWE-bench_Verified')split(str): The split of the dataset to load. (default:'test')input_prompt(str): The prompt template to use for the task input. (default:'Please solve the following coding issue:\n\n{issue_text}')scorer(Scorer | list[Scorer] | None): The scorer to use when evaluating. If None, uses the default scorer. (default:None)sandbox_type(str): The sandbox provider to use (e.g., “docker”, “k8s”, or a custom registered provider). (default:'docker')image_name_template(str): Image name template with{org},{repo},{issue},{id}, and{arch}placeholders. (default:'ghcr.io/epoch-research/swe-bench.eval.{arch}.{id}:latest')arch(str | None): The architecture to use for the image (e.g., “x86_64” or “arm64”). If None, auto-detected from platform. (default:None)sandbox_config(Callable[[str, inspect_ai.dataset.Sample], SandboxEnvironmentSpec] | None): Optional custom function to create sandbox specs. Receives (sandbox_type, sample) and returns a SandboxEnvironmentSpec. The resolved image name is available in sample.metadata[“image_name”] and allow_internet in sample.metadata[“allow_internet”]. If None, uses default config. (default:None)allow_internet(bool): Whether to allow the sandbox to access the internet. (default:False)tool_timeout(int): Timeout in seconds for bash, python and text_editor tools. (default:210)revision(str): The HuggingFace dataset revision to use. SWE-bench datasets are actively maintained, so pinning to a specific revision ensures reproducibility. (default:'c104f840cc67f8b6eec6f759ebc8b2693d585d4a')kwargs(Any): Additional arguments passed to Task constructor.
swe_bench_verified_mini
split(str): Dataset split to use. (default:'test')input_prompt(str): Prompt template for the task input. (default:'Please solve the following coding issue:\n\n{issue_text}')scorer(Scorer | list[Scorer] | None): Scorer to use for the evaluation. If None, uses the default scorer. (default:None)sandbox_type(str): The sandbox provider to use (e.g., “docker”, “k8s”, or a custom registered provider). (default:'docker')image_name_template(str): Image name template with {id} and {arch} placeholders. Defaults to Epoch AI’s pre-built images (DEFAULT_IMAGE_TEMPLATE). (default:'ghcr.io/epoch-research/swe-bench.eval.{arch}.{id}:latest')arch(str | None): Architecture for the image (e.g., “x86_64” or “arm64”). Auto-detected if None. (default:None)sandbox_config(Callable[[str, inspect_ai.dataset.Sample], SandboxEnvironmentSpec] | None): Optional custom function to create sandbox specs. Receives (sandbox_type, sample). See swe_bench() for details. (default:None)allow_internet(bool): Whether to allow internet access in the sandbox. (default:False)tool_timeout(int): Timeout in seconds for bash, python and text_editor tools. (default:210)kwargs(Any): Additional arguments passed to Task constructor.
Dataset
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
Issue: napoleon_use_param should also affect “other parameters” section
Problem:
Currently, napoleon always renders the Other parameters section as if napoleon_use_param was False, see source ``` def parse_other_parameters_section(self, section): # type: (unicode) -> List[unicode] return self._format_fields((‘Other Parameters’), self._consume_fields())
def _parse_parameters_section(self, section): # type: (unicode) -> List[unicode] fields = self._consume_fields() if self._config.napoleon_use_param: return self._format_docutils_params(fields) else: return self._format_fields(_('Parameters'), fields) ```
Other Notes
Running the benchmark
``swe_bench.pyfile containsswe_bench``` function, which creates an instance of a SWE-bench Task:
from inspect_ai import eval
from inspect_ai.agent import react
from inspect_ai.tool import bash, python
from inspect_evals.swe_bench import swe_bench
# Create an agent that only uses bash, and an agent that only uses python
bash_agent = react(tools=[bash(timeout=30)])
python_agent = react(tools=[python(timeout=30)])
# Compare how these two agents perform.
task = swe_bench(dataset="princeton-nlp/SWE-bench_Verified")
sample_ids = ["sympy__sympy-22914", "sympy__sympy-13878"]
bash_log = eval(
task,
model="openai/gpt-4o",
solver=bash_agent,
sample_id=sample_ids,
)
python_log = eval(
task,
model="openai/gpt-4o",
solver=python_agent,
sample_id=sample_ids,
)You can filter to specific instances and override the solver via the CLI:
uv run inspect eval inspect_evals/swe_bench --model openai/gpt-4o \
--sample-id sympy__sympy-22914,sympy__sympy-13878 \
--solver my_package/my_agentSee Task Options for details.
By default, this task sets message_limit=30 to keep runs bounded. You can override this at runtime with the standard --message-limit option:
uv run inspect eval inspect_evals/swe_bench --model openai/gpt-4o --message-limit 60Comparing to official swe-bench baselines
Submissions to the official SWE-bench leaderboard often come with a set of trajectories and per-swebench-instance results. To download these baselines, you need to follow the instructions at https://github.com/swe-bench/experiments?tab=readme-ov-file#-viewing-logs-trajectories to set up the AWS CLI, and download the baselines:
./download_baselines.shThis means that you can compare the performance of your agent not just on the full dataset, but also on subsets of that dataset. This is often useful when trying to run smaller, cheaper experiments. To make this comparison easy, we provide a scorer that will calculate the average performance of an existing baseline on that set of trajectories:
from inspect_evals.swe_bench import swe_bench, swe_bench_baseline_scorer, swe_bench_scorer
from pathlib import Path
from platformdirs import user_cache_dir
baseline_dir = Path(user_cache_dir("inspect_swebench_test")) / "swebench_baselines"
scorers = [
swe_bench_baseline_scorer(
str(baseline_dir / "20240620_sweagent_claude3.5sonnet"),
name="SWE-agent_3.5_sonnet",
),
swe_bench_scorer(),
]
task = swe_bench(
dataset="princeton-nlp/SWE-bench_Verified",
scorer=scorers,
)
eval(
task,
model="openai/gpt-4o",
sample_id=["sympy__sympy-22914", "sympy__sympy-13878"],
)This will lead to both numbers being reported in the final output, allowing you to compare baselines:
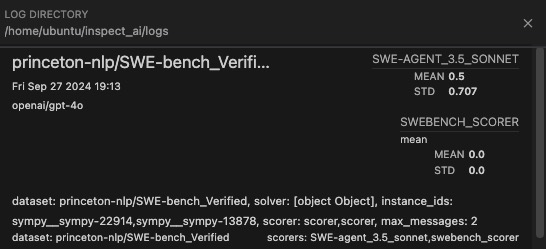
Parity with the original implementation
We keep track of any known issues with our scoring. We recommend that before submitting to the leaderboard, or comparing to public results in a paper, you use the save_outputs_to_swebench_format function to score with the original implementation:
from inspect_evals.swe_bench import swe_bench, save_outputs_to_swebench_format
logs = eval(swe_bench(), model="openai/gpt-4o")
save_outputs_to_swebench_format(logs, "./swebench_formatted_outputs/")You can then use the CLI to score these with the original implementation (as described in their README):
python -m swebench.harness.run_evaluation \
--predictions_path path-to-outputs \
--max_workers 4 \
--run_id check-outputsChangelog
[4-C] - 2026-04-21
- Replaced deprecated
basic_agent()withreact()as the default agent. This fixes a pathological case wherebasic_agent()would loop on repeatedcontent_filterstops until hittingmessage_limit. It also changes the stall-nudge message (sent when the model stops without calling a tool) to append a reminder to call the submit tool — a one-sentence prompt addition that may bias models toward earlier submission.
[3-C] - 2026-04-01
- Increased the tool timeout from 180 to 210 seconds due to new minimum enforced by inspect_ai v0.3.199.
- Added configurable
tool_timeoutparameter with a warning when the value is below the minimum.
[2-B] - 2026-02-16
- Migrate version to new scheme. See #907.
- Simplified sandbox configuration to support multiple providers (Docker, Kubernetes, Modal, and custom) out of the box via the
sandbox_typeparameter. - Added
sandbox_configparameter for fully custom sandbox setups. - Removed
solverandinstance_idsparameters in favour of the framework’s built-in--solverand--sample-idoptions.
[1.0.1] - 2025-12-18
- Adds backoff policy for functions that connect to huggingface servers.